
Introduction
Word embeddings are numerical representations of words in a continuous vector space, by learning the distribution of words in text. They capture both semantic and syntactic relationships between words, making them suitable for various downstream Natural Language Processing (NLP) tasks. Typically, words with similar meanings are mapped to nearby points in the vector spaces. Word Embedding map words to high dimensional vector spaces.
Foundational Concepts of Word Embeddings
Distributional Hypothesis
The Distributional Hypothesis states that words occurring in similar contexts tend to have similar meanings. This principle is mathematically leveraged by analyzing co-occurrence statistics in large corpora. For instance, if “apple” frequently co-occurs with words like “fruit,” “juice,” or “pie,” and “orange” co-occurs with similar terms, their vectors will be spatially proximate in the embedding space. This hypothesis underpins all vector semantics models, enabling them to capture semantic relationships by leveraging structural patterns in language. Mathematically, the similarity between words 
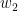

Dimensionality Reduction
Traditionally, the method of one hot encoding, which is, assigning each word a high dimensional vector with a single non-zero entry, is used for text representation.
Instead of using high-dimensional one-hot vectors which are computationally inefficient besides its sparsity, embeddings reduce the dimensionality to focus on salient features. Techniques such as Singular Value Decomposition (SVD) and Latent Semantic Analysis (LSA) are often used in frequency-based methods.
Semantic Representation
The embedding space is structured such that similar words are close together. For instance, if 

The vector proximity is measured by the Cosine Similarity, which is, the cosine of the angle between two vectors.

A small Euclidean distance between 



Such operations reflect the model’s ability to encode lexical relations (e.g., gender, roles) algebraically, mirroring human intuition about language.
Contextual Information and Generalization
Embedding models capture context by analyzing the surrounding words. This allows the model to generate different representations for polysemous words based on their usage:

For example, the word “bank” in “I deposited money at the bank” and “I sat by the river bank” receives distinct vectors. In this case:

This is achieved through architectures like transformers (e.g., BERT), which use self-attention mechanisms to weigh the importance of different words in the context window. By considering the entire input sequence, the model learns to disambiguate polysemous words and infer nuanced meanings.
This adaptability enhances generalization to unseen words by leveraging morphological patterns or syntactic roles. For instance, a model trained on “unhappy” → “happy” (prefix “un-“) can infer the meaning of “unfair” by analogy, even if not explicitly seen during training. Contextual embeddings thus bridge the gap between raw text data and human-like linguistic understanding, enabling applications like machine translation and sentiment analysis.
Traditional Word Embedding Techniques
There are two main types of word embeddings:2
- Sparse Models (Frequency-Based): Measures frequency of word occurrence in text. Examples includes Term Frequency-Inverse Document Frequency (TF-IDF), Pointwise Positive Mutual Information (PPMI) and Co-Occurrence Matrix and SVD.
- Dense Models (Prediction-Based): Captures meaning of words in a compact way. This includes Static embeddings (Word2Vec, GloVe, and FastText) and Contextual Embeddings (ELMo and Flair)

Leave a comment